What is the job of operations and development? Most would say development builds systems and operations makes sure the environments are reliable and efficient. This creates a dichotomy as one the biggest causes of ‘breakage’ or unreliability in environments is the introduction of change, which is what required of the development teams. The other biggest cause is human error – ‘fat finger’ syndrome or just some other small mistake that has unintended consequences. However, as you may well understand, the job of both development and operations is to enable the business to achieve its goals (and therefore keep the dev and ops teams employed).
There are a number of ways to resolve this dichotomy, most of which are complementary. This article is about a superset of some of these methods and techniques – Infrastructure as Code. So what is infrastructure as code? My definition of infrastructure as code is as follows:
“Infrastructure as code takes many of the tools, techniques and practices from software development and applies them to technology infrastructure. It incorporates automation and by explicitly defining the infrastructure as sets of instructions that can be executed by automation technology, allows the maintainability, manageability and repeatability that characterises software.”
While this is probably an oversimplification, it incorporates the key ideas in infrastructure as code, these being:
- Automation
- Infrastructure above the physical hardware being really treated as software (it always was)
- Incorporate development, test, release as a cycle in infrastructure
- Fix the code then ‘compile’ and retest rather adjust ‘live’
- Versioning and migration paths for infrastructure
The following model illustrates where infrastructure as code operates across the overall ‘stack’.
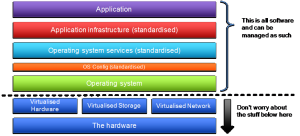
Why has this come about? From a top down perspective, essentially the virtualisation of hardware, storage, networking and cloud along with things like containers, has moved the practice of infrastructure management from the role of cables, boxes, cards, plugs and command lines on machines to code driven automation. The cloud has been a major driver and techniques from the cloud are now being applied to existing infrastructure. The cloud providers needed a way to operate at mass scale and so developed sets of tools and API’s that gave them access what was required in a focussed way. This benefit was then passed on the customers of their services who found it easier to manage which then intern encouraged those customers to look at ways to treat their internal infrastructure in the same way. This desire has been taken on by the ‘cloud washing’ enterprise software vendors who have either bought companies to give them the capabilities to tried to adapt existing products.
From a bottom up perspective, and this is where the streams of devops and infrastructure as code, merge. The majority of seasoned operations engineers will have a set of scripts that allow them to perform sets tasks repeatedly. This led them to look for additional ways to perform changes reliably and efficiently and across multiple machines at the same time. At a similar time, many were/are dabbling with cloud for their own knowledge and or applying these techniques to the infrastructure in their own home. They found that defining the infrastructure as software based resources gave them higher flexibility and better reliability and the ability to return to previous configurations easily. This made their jobs easier and so pushed for the same or similar tools and techniques to be incorporated into their work.
This merge of top down and bottom up is creating a powerful direction in the evolution of infrastructure.
Business benefits
So if this is a direction that does not seem like stopping, there must be some business benefits to rather than just being ‘cool’. The answer to this is that is hits the majority of items business cares about when dealing with a non core part of their business – speed, customer service, cost reduction, risk management and compliance.
Customer service
- Increase reliability of change
- Less downtime
- Enable delivery of overall outcomes more quickly
Speed
- Effect change quickly
- Take infrastructure off the critical path
- Increase change rates
Cost reduction
- Manage more environments with existing resources
- Increase the amount of change for same or less cost
Risk
- Easier testable change
- Rollback capability
Compliance
- Version control
- Process driven
- Audit trail of change
Technical benefits
So we have business benefits, what about technical benefits? Let’s put a situation together – you have a server that is not responding or unreachable. A check shows that the server has crashed, you then remember how difficult it was to configure that server with all the require software and versions. What should the order be? What versions are required? This would be a dreaded moment but with infrastructure as code this becomes a simple matter of checking out the server definition and applying it via the appropriate software.
Using infrastructure as code means writing code (duh) but doing this is in a high level descriptive language rather than cryptic command line statements (though this can be incorporated). But this also means using the software development practices such as testing, small deployments, version control, using patterns, modularity and reuse. It is not the same as infrastructure automation which is executing and replicating multiple steps over a number of machines.
Typical benefits seen include:
- More predictable outcomes
- Testable changes
- Differences between versions can be easily identified
- Process enforcement
- Reduced incidents
- Use of patterns
- Modularity and reuse – with respect to the code
- Scripts acting as documentation for your infrastructure
Limitations
Probably the biggest limitation with infrastructure as code at the moment is support on the Microsoft stack. Yes, the tools will run on Windows but they are probably only about 50% of the way there. Azure is a different story though due to the API access inherent in the Azure ecosystem.
N-tier applications (especially across different platforms) make the the coding exponentially more difficult.
New tools require new skills and skills in the market are currently limited.
Cloud
Cloud has driven the take up of infrastructure as code (even though the history of infrastructure as code goes back to mid 90’s) as the cloud providers have provided RESTful API’s to access the services to create manage and delete machines instances on their infrastructure as there is no direct access to their data centres. As this has become the norm in cloud delivery it is understandable that people have wondered whether this is possible on their own infrastructure or managed services.
Devops vs. Infrastructure as code
Devops and infrastructure as code are not the same thing. Infrastructure as code helps devops but devops is not encompassed by infrastructure as code. My view of the difference is that devops ops is a process, people and cultural change where as infrastructure as code is a set of tools and techniques. It is perfectly possible to do infrastructure as code without devops but it is much more difficult to do devops without embracing infrastructure as code.
What do you need?
Infrastructure as code needs a tool chain, process, skills and a willingness to change. We will look at the details in other articles but here is a sample tool chain. It contains the major elements needed to support infrastructure as code and aligns them along the general direction of the process.
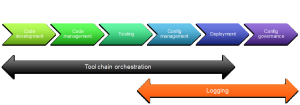
For each of the elements a quick explanation and some of the tools in the element. Be aware that tools have overlapping capabilities.
Code development
At its most basic, a text editor will suffice but there are Eclipse based tools for various DSL’s (domain specific languages) as well as enhanced text editors with plugins for common tools used in infrastructure as code. Many of these will integrate with some of the code management tools available. Visual Studio also has plugins for for DSL’s.
Writing efficient code is still the job of the coder but tools with the plugins will enable syntax checking, code completion etc., though not to the same extent as one of the general coding languages such as C#, Java, Swift etc.
Tools include – vi, emacs, text edit, ultraedit, Eclipse, Visual Studio, and many others
Code management
The choice of code management tool is probably less important than actually having one! A share on a file server is not an effective code management tool! Typically, the choice comes down to what the development team are using and/or whether there is an existing implementation.
Code management tools generally come in 2 flavours client server or peer to peer. Peer to peer seem to be the flavour of the month at the moment and they have some advantages in allowing all ‘developers’ their own access to the entire code tree at once.
Tools include – Subversion, Git, Bitbucket, Visual Studio TFS, Perforce, Bazaar
Testing
Being able to test code is a fundamental part of coding. Test driven development is one technique that cab significantly improve code. This works by defining tests that can be executed by the code based on an input to deliver and expected output. While this may seem a bit redundant when your code says “apache, ensure => installed” there are still good reason to devise some tests. The second is to ensure that the code produces the environment intended and did not have unintended consequences on other parts of the infrastructure. So using configuration management tools to check the before and after state across the environment and ensure that the differences are only the ones intended. This should of course not be done on the production environment but your test and staging environments. It also has the handy feature of allowing back out testing as well, if you choose to do so.
Configuration management
This is the heart of infrastructure as code as majority of execution of the ‘code’ happens here. The configuration management tools are not your CMDB though and are usually based around a client server model. A central server holds the current or available configurations and the client pulls down the appropriate configuration to the instance to be configured and the client executes the code.
Tools include – Chef, Puppet, Ansible, SaltStack, RunDeck etc.
Deployment
Deployment can take two forms being the deployment to the instance to be configured and the deployment of code to the configuration management tool. The deployment to the instance to be configured is usually covered by the configuration management tool. The deployment from the code management tool to the configuration management tool is the same problem that developers have in migration code between environments. This is usually covered by orchestration tools.
Tools in the orchestration space include – Vagrant, Jenkins and others
There is a third category coming to the fore and this covers the deployment of complete stacks. The code in this case describes the ‘data centre’ environment and all the pieces to enable the delivery of the environment including the configuration management tools. These usually have their own DSL as well but are newer tools.
Tools in this space include – Terraform, CloudFormation (AWS only), etc.
Configuration governance
Configuration governance involves the use of the configuration management tools to ensure that configuration drift is eliminated and if configuration drift is detected then the approved configuration and be reapplied to returned to on the instance. While to tools can identify the drift, it is up to internal process and governance principles to decide what to do about the drift. This is the key to governance – having clear guidelines and actions to be taken that have been agreed.
The drift usually occurs because of changes implemented that have not gone through the infrastructure as code process i.e. someone has made a change (usually to fix something) that has not amended the configuration in the code and then directly applied.
Tools include – Puppet, Chef, ScriptRock, Qualys etc.
Where to start
With so many choices and decisions to make often starting is one of the hardest areas. The advice is to start small and contained but make your key choices in delivering your tool chain. This is where the cooperation with the developers needs to be factored in, and the shared use of existing or new technology must be considered.
Keeping track of success and benefits will help expand the use on infrastructure as code by demonstrating the benefit and tend ploughing money saved, back into expanding the use of the tools.
Cloud is a good place to start for new implementations as, cloud almost requires the use of infrastructure as code and the cost of tools and implementation can be included in a cloud business case. This is easier to get through a business case process than trying to justify and infrastructure as code project where many of the benefits are intangible and longer term.
Who are the players
Like many trends in the industry recently the infrastructure as code direction has come out of the open source movement and many of the tools have open source versions and a paid version that provide increase capability, guaranteed compatibility and support. There are many blogs, conferences, un-conferences and meetups dedicated to this subject and related subjects.
The big names in infrastructure as code are the usual suspects but these tend to only cover part of the problem space but a significant part. These are the configuration management tools providers being, Puppet, Chef, Ansible, SaltStack.
The traditional infrastructure software vendors are trying to get involved (BMC, CA, IBM, etc.) but there more traditional automation tools tend to be stuck within that eco-system and do not lend themselves well to code management tools, dev/test/stage/prod release cycles. A number of these players have bought new companies that provide tools that better serve this market and are trying to integrate them into their existing product lines.
Puppet and Chef have the same background though Puppet branched off from Chef a while ago. They both work essentially in the same manner with some implementation differences. The main difference is the Chef uses Ruby as its language while Puppet uses its own DSL but the roots in Ruby and JavaScript can be seen.
A further article will discuss the tools in more detail.
What does success look like?
If you are heading down the path of infrastructure as code success can be measured in a number of ways. However, I believe that you are on the way to success when you have the following:
- Version control is implemented
- Automated testing
- Staging environments are generated
- Architecture for infrastructure as code is well defined
- Processes are documented and followed
Along with this go measures. These might be aspects such as:
- Time to deploy
- Time to build
- Number of changes (cadence)
- Peer reviews of code
- Changes per incident
These measure need to be built into the process not added as an afterthought!